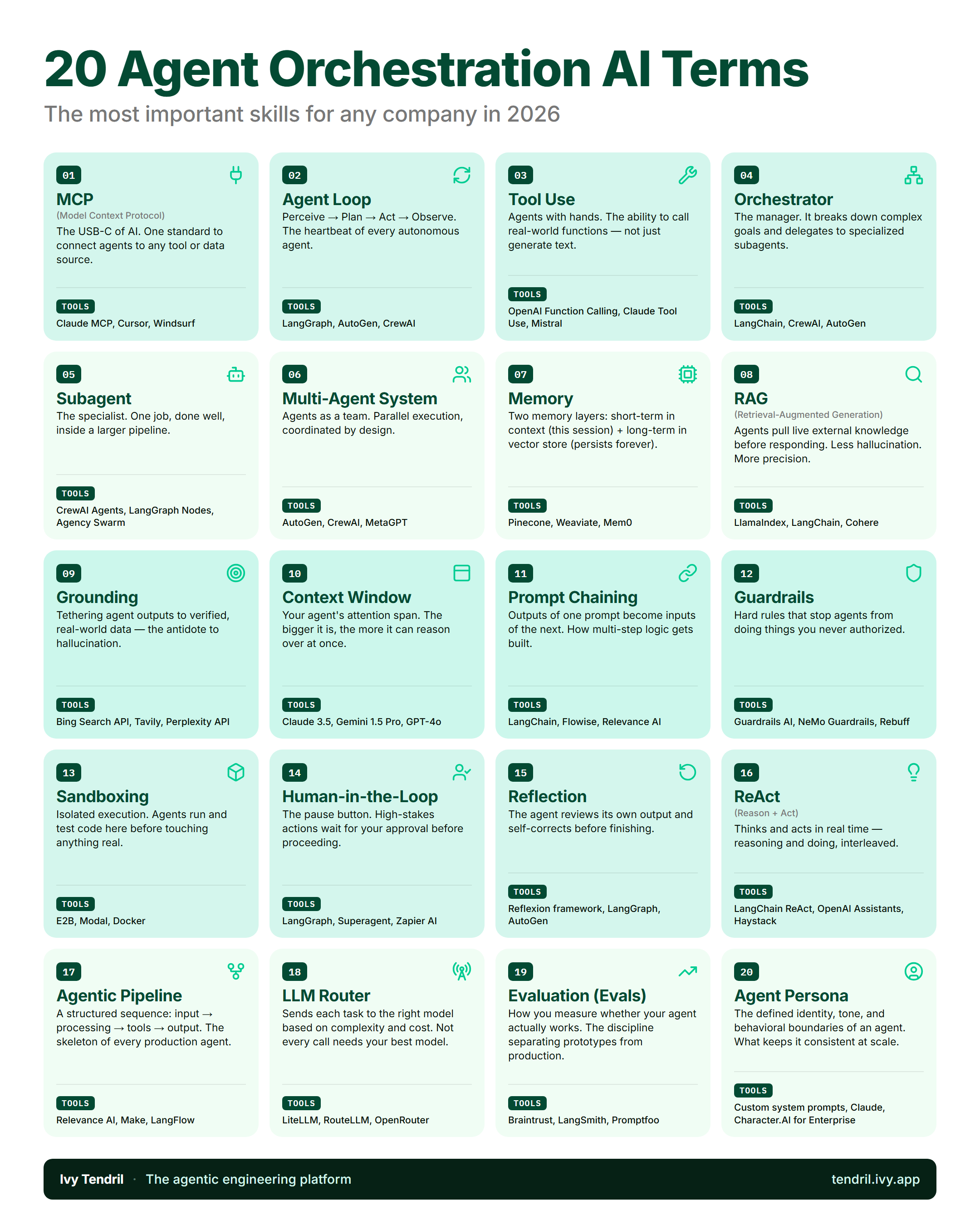
The new vocabulary of AI development, defined the way Ivy uses it inside Tendril.
Agent orchestration is the engineering skill of 2026. Mass adoption is here: Claude, Codex, Cursor, and Copilot are in every developer's hands, and the model itself is becoming a commodity. The new competitive question is whether a team can run twenty parallel agents without blowing the AI budget or shipping garbage.
In April 2026, Uber publicly confirmed it had burned its entire annual AI budget in four months. Uber rolled out Claude Code to five thousand engineers in December; by February usage had doubled and parallel agents were scaling token cost nonlinearly. The stack lacked the budget enforcement, attribution, and approval gates that would have caught any of it before it landed on the CFO's desk.
At Ivy we think the wiring is the product. Our bet is a fully integrated setup: a developer driving Claude locally, and a Tendril CLI that pushes long-running and parallel work to a server pipeline that runs around the clock under guardrails the team controls. Skills like /plan, /approve, and /e2e offload the heavy work with persistent memory, hallucination checks, credit caps, and audit trails. Wire this layer well and the advantage compounds for years; skip it and your logo lands on next year's headline instead of Uber's.
That layer needs a shared vocabulary, and right now it doesn't have one. What one team calls an orchestrator is another team's router. Half of LinkedIn calls everything ReAct. The word "agent" gets stretched to cover anything from a single API call to a multi-week autonomous research run. The list below is the working vocabulary as it stood at Ivy's mid-2026 review of the field — twenty terms, twenty short definitions. If your team uses one of these words differently, that's fine. A shared definition is the first step toward a shared workflow.
1. MCP (Model Context Protocol)
Anthropic's standard for connecting agents to tools and data sources. Think USB-C for AI: one cable, many devices. Before MCP, every coding agent had its own bespoke plugin format. With MCP, your Postgres connector, your Slack reader, and your custom internal-tooling MCP server all plug into Claude Code, Cursor, Windsurf, Codex, and anything else that speaks the protocol. The Ivy Framework ships an MCP server out of the box, which is what lets agents inside Tendril extend the orchestrator they run on.
2. Agent Loop
The four-step heartbeat: Perceive, Plan, Act, Observe. The agent reads state, decides what to do, executes a tool call, observes the result, and starts again. Every "agentic" system you'll encounter (LangGraph, AutoGen, CrewAI, your own homegrown one) is some elaboration of this loop. The interesting design question is when to terminate it.
3. Tool Use (Function Calling)
Tool use is what turns a chatbot into an agent. The model receives a list of available tools and decides when to call them, with what arguments. OpenAI's function calling, Claude's tool use, and Mistral's variant are minor variations on the same idea. Without it, the model can only generate text.
4. Orchestrator
The component that owns the workflow. It breaks a goal into steps, dispatches subagents to each step, enforces budgets, and decides when to stop. LangChain, CrewAI, and AutoGen all ship orchestrators of varying ambition. Tendril is one too. The orchestrator is also the only layer that knows what a "task" is, which is why it is the only layer that can enforce per-task spend or per-role guardrails.
5. Subagent
A specialised agent inside a larger pipeline. Each subagent does one thing well. In Tendril, the planner only reads code, the executor only writes code, and the reviewer only checks output against the plan. Single-responsibility holds for agents the way it does for microservices, and for the same reason: scope creep is where reliability dies.
6. Multi-Agent System
A coordinated team of subagents, running in parallel where the work permits and serially where dependencies force it. AutoGen and CrewAI position themselves around this idea. MetaGPT goes further, assigning explicit company-style roles. The honest take: most teams in 2026 do not yet need a five-agent setup. A team of three (planner, executor, reviewer) clears most enterprise workloads.
7. Memory
Short-term memory is the context window, which evaporates the moment the session ends. Long-term memory is what an agent carries across sessions, usually a vector store (Pinecone, Weaviate) or a structured store (Mem0). Without long-term memory, your agent re-learns your codebase every Monday. Tendril stores this as Memory/ folders inside each promptware, alongside persistent server-side memory.
8. RAG (Retrieval-Augmented Generation)
Before answering, the agent retrieves relevant documents and feeds them to the model as context. LlamaIndex, LangChain, and Cohere all sell RAG infrastructure. The premise: a model grounded in real source material hallucinates less than a model relying on training data alone. RAG is the lazy answer to "should we fine-tune?", and usually it is also the correct one.
9. Grounding
Tethering agent outputs to verifiable real-world data. Bing Search, Tavily, and Perplexity APIs are common grounding sources. The distinction from RAG: RAG is a technique, grounding is the outcome. A well-built RAG system grounds; a poorly-built one retrieves noise and the model hallucinates against it anyway. Verification gates are Tendril's grounding mechanism for code: the build and the tests have to agree with the AI reviewer before the diff advances.
10. Context Window
How much text the model can hold in mind at once. Claude 3.5 sits at 200K tokens, Gemini 1.5 Pro at 1M, GPT-4o at 128K. The number is less important than how the model uses it. A 1M-token window does not guarantee the model attends to anything past the first 50K. Treat context window size as an upper bound, not a working size.
11. Prompt Chaining
The output of one prompt becomes the input of the next. LangChain made the name famous; Flowise and Relevance AI ship visual builders for it. Most "agents" are still prompt chains underneath, which is fine when the work is predictable. The moment the workflow needs to branch on results, you have left chaining and entered orchestration.
12. Guardrails
The rules the agent is not allowed to break, even when its instructions tell it to. Guardrails AI, NeMo Guardrails, and Rebuff sit in this category. Guardrails enforce things the prompt cannot: no production calls without approval, and no spend past a cap. The Uber budget incident from April 2026, where the entire year's AI budget burned in four months, is what happens when guardrails live only as a slide in a strategy doc instead of as code in the orchestrator.
13. Sandboxing
Where agents run code that has not been reviewed. E2B, Modal, and ephemeral Docker containers are the common stack. The agent can install packages, hit external APIs, and blow up the filesystem without any of it landing on your machine or your network. Tendril runs every plan inside an isolated git worktree, which is the same idea applied to source-controlled code: the agent never touches your main branch until you approve the diff.
14. Human-in-the-Loop
The pause button. High-stakes actions wait for explicit human approval before proceeding. LangGraph, Superagent, and Zapier all support this pattern. Tendril's doctrine sets the count at exactly two: approve the plan, approve the diff. Zero would be reckless, and any more becomes ceremony.
15. Reflection
The agent reviews its own output and corrects it before declaring done. Self-Refine, Reflection 70B, and various LangGraph patterns make this explicit. Reflection catches reasoning gaps but rarely catches hallucinated APIs. Pair it with verification (gates that compile, run, or query reality) rather than treating it as a substitute.
16. ReAct (Reason + Act)
Thinking and doing, interleaved. The model writes a thought ("I should check whether the file exists"), then takes an action ("open file.py"), then reads the observation, then thinks again. ReAct is the default pattern for most coding agents in 2026: LangChain ships a ReAct module, and OpenAI Assistants are ReAct-shaped under the hood. The original 2022 Yao et al. paper is still worth reading.
17. Agentic Pipeline
Input, planning, tools, output, review. The skeleton of every production agent. Make, LangFuse, and Relevance AI sell visual versions of the same idea. Workflow engineering lives at the pipeline level: rather than tweaking a single prompt, you tune the pipeline that runs it, adding gates, swapping models per step, and attaching memory to specific stages. The pipeline is what scales, while individual prompts get re-tuned every month regardless.
18. LLM Router
Sends each task to the right model based on complexity and cost. LiteLLM, RouteLLM, and OpenRouter sit in this slot. Not every call needs Opus. Bug-triage routinely sits inside Haiku's competence envelope, and routing those calls correctly is often a clean 60% spend cut on a fleet of agents. Tendril's promptware profiles (deep / balanced / quick) are an explicit router: every agent declares its needed model class, and the orchestrator dispatches accordingly.
19. Evaluation (Evals)
How you actually measure whether your agent works. Braintrust, LangSmith, and PromptLayer sit here. Evals are the discipline that separates prototypes from production: a system you cannot measure is a system you cannot improve. Forget BLEU and other academic benchmarks. The metrics that matter for orchestration are verification pass rate on the first try, human-correction rate per plan, and cost per shipped outcome.
20. Agent Persona
The agent's defined identity, tone, and behavioural boundaries. What keeps it consistent at scale. System prompts, Claude personas, and Character.AI for Enterprise sit in this slot. Persona matters less for narrow code agents (whose voice nobody reads) and more for customer-facing agents and for multi-agent systems where the personas have to coordinate without colliding. The risk to watch is persona drift across long sessions, a known failure mode the field has not yet fully solved.
One thing to take from this list: the vocabulary is not the work. Knowing the words for orchestrator, guardrail, and eval matters because shared language is the first piece of a shared workflow, not because the words themselves ship anything. The work is wiring them up so a junior engineer can run a $200/month skunkworks budget without surprises, and so a platform team can answer "what did the agents do this week?" with logs instead of a guess.
Ivy Tendril exists to make that wiring boring. Vocabulary is the easy part.
Talk to us: renco@ivy.app · tendril.ivy.app · github.com/Ivy-Interactive/Ivy-Tendril
